$ OLAP笔记
$ OLAP引擎对比
大数据技术发展到2021年,底层的存储、计算、调度引擎似乎都已经形成了事实上的标准,但是OLAP领域却一直百花齐放,没有出现一种统一的OLAP引擎,究其原因是没有一种引擎都能适用于各种场景,或多或少都存在这样那样的不足。现就工作中接触到的OLAP引擎做一个总结对比。
$ Kudu+Impala
Kudu+Impala在我司是最主要的OLAP引擎,因为我司的业务大量场景的数据是实时更新的业务数据,业务方对数据时效性要求较高(分钟级),Kudu支持实时的upsert操作,在没有引入数据湖技术之前Kudu是为数不多的解决方案。
当然在实际的项目使用中还是做了一些妥协,比如impala本身没有缓存,为了避免高并发对impala资源的消耗,将impala聚合后的数据导出到MySQL,应用连接MySQL进行查询。另一方面我们有的SQL比较重,涉及到多张大表join之后做聚合计算,执行时间长,运行不是很稳定,这样也能提供一定的缓冲。这种用法会导致数据的时效性在10min这个量级,但是大部分的业务是可以接受的。
这个组合还有一些缺陷比如Kudu启动时间过长,Impala查询经常遇到单节点内存不足的报错,遇到节点挂掉查询直接失败,依赖组件太多等等。
$ ClickHouse
ClickHouse主要用来做多维数据分析,依赖于超高的查询性能,很多业务要求查询响应必须是秒级以内。配合chproxy代理,能够做到查询的缓存,而且批量写入性能能够媲美HBase,甚至可以当作时序数据库来用。据说京东的ClickHouse大表数据量可以达到百亿级别。而ClickHouse的问题是不支持数据更新,join支持的不好,运维成本比较高。
$ Kylin
Kylin支持了一些固定维度查询的报表业务,它在响应速度,查询并发,SQL能力,精确去重等方面令人印象深刻,但是预计算的思想导致数据变更的成本很高,同时依赖的组件也很多。
$ Doris
由于数据模型比较丰富,Doris是相对来说适用场景最广的一个引擎,我司也打算用Doris来统一Kudu,ClickHouse,Kylin各种引擎。在满足功能和性能需求的前提下,可以预见的优点是运维成本极低。Doris目前存在的一个短板就是资源隔离能力不够,如果想要保证重要业务稳定性,Doris核心开发者建议还是做集群层面的物理资源隔离。
Doris使用上需要注意的一点是写入的频率最好控制在分钟级,单表数据量控制在10亿以内。
$ 总结
各个引擎详细对比如下:
| 引擎 | 写入 | 查询 | 运维 | 适用场景 | |||||||
| 点更新 | 时效性 | 预聚合 | 权限 | Join | 精确去重 | 视图 | 并发 | 运维难度 | 复杂度 | ||
| Kudu+Impala | ✔ | 秒级 | ✖ | 列级 | ✔ | ✔ | ✔ | 中 | 中 | 高(依赖Hive,Sentry,zk...) | 实时olap |
| ClickHouse | ✖ | 秒级 | ✔ | 无 | ✖ | ✔(bitmap) | ✔ | 低 | 高 | 高(依赖zk) | 单表,日志分析 |
| Kylin | ✖ | 小时级 | ✔ | 库级 | ✔ | ✔(bitmap) | ✖ | 高 | 中 | 高(依赖HBase,Hive, HDFS) | 固定维度预计算 |
| Doris | ✔ | 分钟级 | ✔ | 表级 | ✔ | ✔(bitmap) | ✔ | 高 | 低 | 低 | 实时olap |
| Presto | ✖ | 小时级 | ✖ | 无 | ✔ | ✔ | ✖ | 中 | 低 | 低 | Hive查询加速,多数据源 |
$ OLAP选型
结合OLAP引擎各自的优缺点,在我司应用的时候选型方案如下:
- 数据量在百万以下的时候用MySQL能扛得住,而且稳定性更高,简单易用
- 数据量比较大,并发低,时效性在小时级,查询明细的场景适合用ClickHouse,这种场景即时数据有更新也能应对
- 数据量比较大,天级或者小时级更新,只有聚合查询的场景适合用Kylin
- 数据量比较大,并发低,时效性要求分钟级,数据只有追加,适合用ClickHouse
- 数据量比较大,时效性要求分钟级,数据有更新,这种场景只能用kudu或者doris了
需要说明的是,往下的场景也能覆盖往上的场景。
| 数据量 | 时效性 | 查询类型 | 更新类型 | 并发 | 引擎 |
|---|---|---|---|---|---|
| 百万及以下 | * | * | * | * | MySQL |
| 千万及以上 | 天级、小时级 | 明细 | * | ? | ClickHouse |
| 千万及以上 | 天级、小时级 | 聚合 | * | * | Kylin |
| 千万及以上 | 分钟级 | * | 追加 | ? | ClickHouse |
| 千万及以上 | 分钟级 | * | 更新 | * | Kudu|doris |
$ OLAP引擎使用规范
实时性不高的场景尽量使用Hive或者Spark
数据批量写入而不是单条写入
控制写入频率
禁止大批量数据导出到离线数仓,容易影响集群稳定性
OLAP引擎里做ETL任务要慎重,容易影响集群稳定性
禁止本地直连生产环境进行调试
$ OLAP计算模型
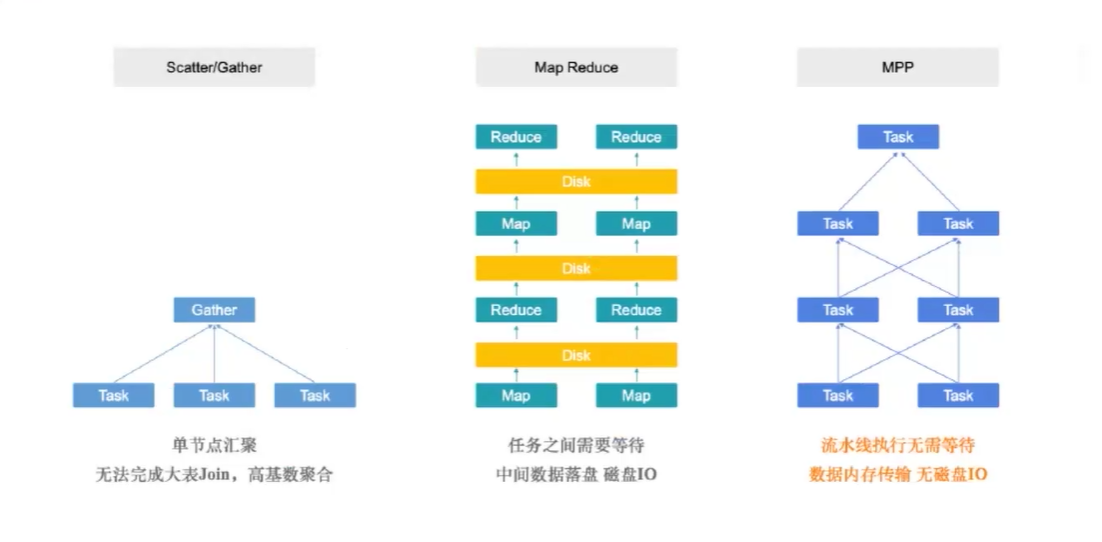
| 计算模型 | 说明 | 优点 | 缺点 |
|---|---|---|---|
| Scatter-Gather | 相当于MapReduce中的一趟Map和Reduce,中间计算结果往往存储在内存中,通过网络直接交换。没有shuffle过程 | 无法完成大表Join,高基数聚合 | |
| MapReduce | 任务之间需要等待,中间数据落盘,多轮迭代 | 失败任务可以重试,适合大数据量ETL操作 | 慢 |
| MPP | 流水线执行,数据内存传输 | 失败任务不可以重试 |
$ 参考
第1章04节 | 常见开源OLAP技术架构对比 (opens new window)
$ 案例实践
$ 有序漏斗/留存分析
Apache Kylin中使用intersect_count()进行计算,参考:
Retention Or Conversion Rate Analyze in Apache Kylin (opens new window)
← Hive解析json数组 数据分析笔记 →