$ Waterdrop学习笔记
以下内容基于waterdrop的v2.x版本。
$ 数据流
$ Spark批处理
Spark批处理引擎的代码逻辑主要在类SparkBatchExecution.scala (opens new window)中,执行流程如下:
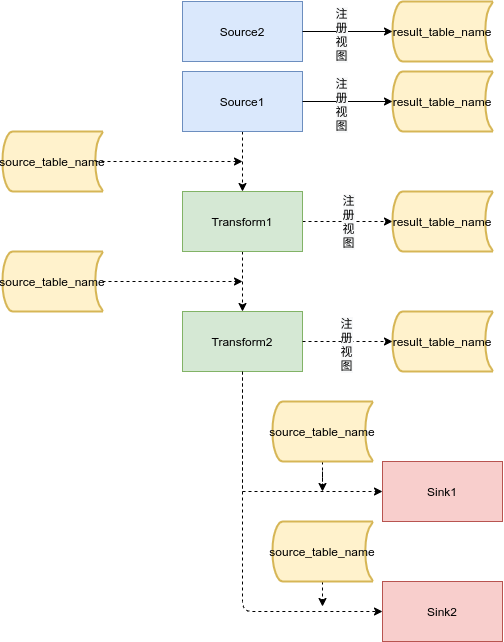
- 执行source部分:source可以有多个,每个source都必须注册成一个临时视图。
- 执行transform部分:当transform的输入为空时则跳过后续transform过程。每个transform的输入表都可以通过source_table_name指定,输出都可以选择性地注册为临时视图。如果没有指定source_table_name,首个transform的输入默认接首个source。同样如果没有指定source_table_name,后续transform的输入默认接上一个transform的输出。
- 执行sink部分:顺序执行每个sink过程,每个sink过程都可以通过source_table_name指定输入表。如果没有指定source_table_name,首个sink过程的输入默认接首个source(空数据)或者最后一个transform的输出。
$ Spark流处理
Spark批处理引擎的代码逻辑主要在类SparkStreamingExecution.scala (opens new window)中,执行流程参考Spark批处理。
$ Flink批处理
Spark批处理引擎的代码逻辑主要在类FlinkBatchExecution.java (opens new window)中,执行流程参考Spark批处理。
$ Flink流处理
Spark批处理引擎的代码逻辑主要在类FlinkStreamExecution.java (opens new window)中,执行流程参考Spark批处理。